
Adam’s Late-Night AI Texts
Adam: So hi, I’m Adam Gordon Bell. This is CoRecursive, and today I have Don.
Don: Hi, I’m Don. I’m here. Yeah, so, uh, Adam’s been obsessed with AI and LLMs for way too long. He keeps sending me tweets and articles. In fact, he sent me a bunch just, like, last night. Like 10 o’clock too. It wasn’t early. It was late, it was late, and I’m like, “What is…”
Adam: I think it was like 9:00.
Don: It was… No, it was like cl- I don’t know, close to 10:00. It was like 9:40 or something. I mean, it’s not like I was busy. It’s fine.
Adam: 9:20, there we go.
Don: 9:20.
Adam: I win this round. Okay.
Don: But you ended at 9:50.
Adam: So basically, OpenAI has a new release, and so they’re out pumping it up.
Don: Yeah.
Adam: And the thing I sent you that I thought was super interesting was this quote from Greg Brockman, who’s the president, uh, of the company.
Don: H-he said:
“I think of Spud as a new base, a new pre-train, and I’d say it’s like we have maybe two years’ worth of research that is coming to fruition in this model.”
And I have no idea what those words mean. What’s Spud? What’s a base? What’s a pre-train? Two years of what?
Three Quotes Don Can’t Decode
Adam: So we’ll get into that. And what was the second one I sent you?
Don: Uh, the other one was older, a leaked memo from inside Google, three years old. A line you had highlighted said:
“We have no moat, and neither does OpenAI.”
And, Moat? Like, what’s… Why are they making castle analogies?
Adam: I mean, I feel like you kind of… You know what a moat means and…
Don: I do. I do know what a moat means. They’re creating walled gardens, right? So, they’re like, “Well, hey, you know, we’re making this thing, and we’ve got billions and billions of dollars in funding,” but there’s nothing that stops somebody else from just doing this thing.
Which is the whole core of what the internet was created for, way back in the day, right?
It was just a bunch of people figuring things out. Everything was open. Then, you know, corporations moved onto the scene, and all of a sudden it’s like, “How can we monetize and make walled gardens and force people into our ecosystems?”
Adam: Third quote I sent you. Do you wanna share that one?
Don: Sure. It says:
R1 is on GitHub, Llama is on Hugging Face, and what’s this 850 billion for?
Adam: Yeah, that one is cryptic, but I feel like this gets at exactly what you are getting at.
But yeah, gonna call this format Stack Trace, working name. We’ll see how that goes. But it’s like, you know, when something blows up and you get a giant stack trace and, you know, you have to kind of figure out what the error is and peel back the layers one by one, right?
So I thought if we could peel back through these quotes from these articles that I thought were super interesting. The Brockman one is brand new, right? It’s now the 29th. I think it was a couple days ago they released their new framework. So I thought if we can walk backwards from whatever the business case to the engineering.
What they’re building, how it works, because none of this makes sense unless you understand what pre-training is, what a base model is, what OpenAI is even doing or, or trying to do with their new models. And once we add some meat onto these bones, maybe we can figure out if these companies make sense, if they’ll be profitable, if the world will change, et cetera.
Don: Yeah. No, that sounds like a good idea.
Why Throwing GPUs at It Just Worked
Adam: Okay. So let’s start with what training is. So did you ever use the old school Copilot where it was like autocomplete in VS Code?
Don: I used something similar in IntelliJ. So I didn’t use VS Code too much, but IntelliJ had like autocomplete and it started getting smarter and smarter, like it would sort of look at the context in which you were writing and try and propose something. I would say that maybe 60% of the time it was useful, but 40% it was way off.
It was like, I don’t want that. And then it would try and– You get into this state where it’s like press a button to autocomplete it. It’s like, but I don’t want to. So now it’s interrupted my flow, right? Because I can’t just press a button or else it’ll spew out all the stuff I don’t want. So I’d have to hit another button to cancel it out.
I don’t know if this is just a me problem, but it got in the way of me actually writing the code of like, “No, leave me alone. You’re suggesting something that’s not useful.”
Adam: I feel like people had different reactions to it. Like some people are still using that form factor, but many people aren’t. But that was part of the first iteration of these LLMs, it was just picking the next token.
So you have all this code, and then it’s like, “Hey, what comes next?” And it tries to guess that. That’s the entire training objective. So before Copilot even launched in 2017, Google published this paper, “Attention Is All You Need,” and it invented the transformer.
The transformer is the T in GPT, right?
And it was just, in Google they figured out Hey, let’s take this transformer thing, let’s feed it all the internet, every Wikipedia article, every book—
Don: Reread it, yeah.
Adam: Everything you’ve ever posted on Reddit is preserved somewhere. And you just get it to predict what the thing is that comes after that, right? And OpenAI, at this point, you know, they were kind of a research lab and, They, they did this Dota 2 battles where they were trying to beat professional players. They had physical robots that were trying to solve Rubik’s Cubes.
They did all this stuff. It was supposed to be a research-y type organization, and the GPT was one of their bets. And it was complicated because to get it to consume all of the internet was this complicated training run, and it was a bit finicky. But it worked, right? Like, it started to become good at predicting this next token, and, as we know, this all, you know, became this huge industry.
But the first thing that they kind of figured out, even maybe, you know, in the very early days, was that Hey, we have something here where if we throw more compute, if we throw more GPUs at this it just gets better."
Don: Yeah.
Adam: That is kind of unusual, right? Most problems, I don’t know, most problems can’t just be solved by give it more CPUs.
Don: I find the opposite, that, uh, throwing more hardware at it is kind of like a trope in our line of work, right? If you, if you have some, uh, some code that’s not well optimized, it’s using a lot of memory, it’s taking a long time, you throw more hardware at it and, uh, problem solved until, you know, until it starts slowing down again.
Adam: That’s true, right? Like, why optimize this code? Yeah, that is a trope. Why optimize this code? Just buy a bigger server.
Don: Just buy a bigger server.
Adam: Yeah.
Don: Just, uh, just upgrade it to the next node size.
Adam: Yeah. So they had this very clear idea, like, “Hey, if we can throw enough computers, then we’ll have AGI or something.
We’ll have something very intelligent,” “Hey, we got something that seems like it can think a little bit. We can’t chat to it yet. And if we just throw more compute at it, it can think even better,” right?
And so let’s just keep doing that.
And they called this process Training, simple enough. Get all the text of the world, feed it to this thing, give it as much compute as you can, we get something smarter and smarter. So this original hypothesis of just scaling up came from 2014, even before the transformers. There was this guy, Ilya Sutskever, and he had this paper called Sequence to Sequence, and he argued that, yeah, with a big dataset and enough compute, success is guaranteed of building, you know, some sort of prediction machine.
Don: What, what does success look like? Like define success. The predictions are only useful if they’re accurate most of the time.
Two Gaming GPUs in a Toronto Basement

Adam: Yeah, so he had come out of, uh, the University of Toronto, this deep learning group, and they had this great success on what had been this really hard problem at the time, which was identifying images, like picking what the things were in images and tagging them. And, uh, people had been competing for all different places to do the best labeling of these images.
And this group what’s the head guy’s name? Hinton. So this is Hinton, right? He was the professor. And, uh, yeah, they beat this benchmark of identifying images. They were just so much better at it, and they did it with, uh, deep neural networks and just a lot more compute, right?
They blew it out of the water and revolutionized the, the field of machine learning. This guy in the background, this is Ilya right here, right? He was one of his students. They started working on this ImageNet, which was an annual computer vision competition, and their submission was called AlexNet, and they trained on two consumer gaming cards that they had in the basement of U of T.
I don’t know, I don’t know a lot about GPUs, but you probably do. So they had two GTX 580s. Is that good or—
Don: Those were good, yeah, those were good cards. I’m still rocking a 1080 Ti. It’s old.
Adam: Yeah, I don’t know. I’m not up on the field of GPUs. But the point is, they were able to use neural nets and they just blew this benchmark out of the water. That had been kind of… People have been inching up, right? Like getting a little bit better at identifying things.
And that year when they submitted, the runner-up got 26.2 of the questions wrong. And they got 15.3. So everybody had been slowly climbing into the 20s, and they just cut it in half. They’re like, “We got everything except these—
Don: But 15%’s actually not not bad. What kind of questions are we talking about?
Adam: It’s identifying all these different things, but for some reason, there’s a lot of dogs in it. So you have to guess the dog breed and circle like, “Oh, this is a whatever.” And the…
Don: That’s better than I would do.
Adam: You… Yeah, cause of all those poodle ones, who knows? Yeah, there’s like a million poodle crosses and…
Three Founders and a Magic Graph
Adam: Yeah. So every researcher in this room grew up to become, uh, very important, ‘cause this was a revolution when they built this, when they beat this using a new approach, right? So three years later, based on this, Ilya, this guy, he co-founds OpenAI, and he co-founds it with Sam Altman and Brockman was the original quote, and I’m sure you’ve heard of Sam Altman. Then there was this other party, Elon Musk—
Don: Who’s that guy? I don’t…
Adam: Elon Musk?
Don: I haven’t heard.
Adam: Yeah. Oh, interesting.
Don: Familiar.
Adam: Anyways, so Ilya’s like, he’s the research brains, right? He’s the researcher who does all the research. Brockman is like the engineer, you know, let’s actually productize all this, right?
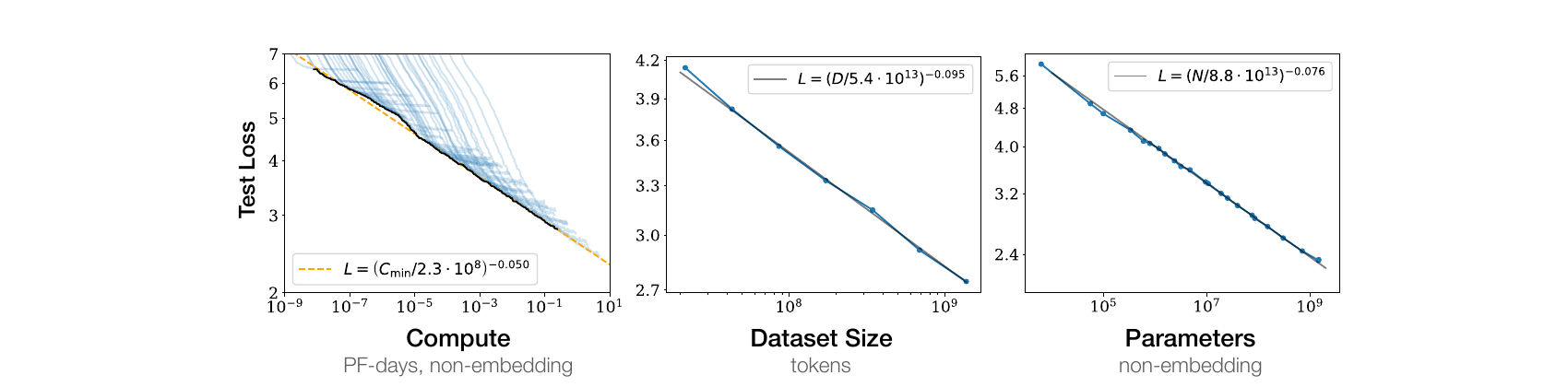
Adam: So he becomes chief scientist, and then in 2020, um, there’s a paper published. They actually write a formal, uh, paper that’s more than just vibes that says like, “Here is how, given more compute, we can learn more things,” right?
Like, “Here’s the formula.”
And this is their paper. They say like, “Here’s how we do this.” Which is interesting because before this, all these people were competing for ImageNet and it was like you try a bunch of things, right? You have your pile of GPUs in your basement or in your research lab, and it’s like try some stuff, see if you can do better.
But here they’re like, “Dude, we have a graph.”
Don: I mean, obviously the graph was based on some like concrete data, ‘cause I mean, anybody can make a graph and be like, “Oh, you know, I improved the performance by 20% when I increased the hardware by this much, so therefore my graph goes to the moon.”
Adam: Yeah. Or like, uh, you got married 10 years ago, so if by the time I’m 60 I will be married five times.
Don: You need a solid base of some comprehensive data points at the beginning of the graph to make a prediction.
Adam: So I think it makes sense to be skeptical, but from their perspective, there was something great they could do with their graph, right? Which is, say like, “Hey, if you give us more money, we can buy more GPUs and per our graph, we’ll have a smarter thing.”
And so it becomes a fundraising thing.
Don: Well, I mean, yeah, what, w- why else would you make a graph unless, you wanted to, you know, convince somebody to give you money?
Adam: Yeah, like I have this thing here on the graph, but think what I could do instead of those two damn GPUs if I had all the highest end ones that I could fit in this room. Oh, now we’re talking, right? So this is sort of what they do, right? The kind of this graph and this published paper, uh, you know, and it’s published in a reputable place, so people have vetted it.
Adam: Yeah, so originally it was financed by this guy who you said you didn’t know, Elon Musk, and I don’t know. He was just like, “Cool. Let’s build the super AGI of the future,” right? There was a little bit, in the early days of all the people involved in this where they all believed in this idea that we could build a super human intelligent machine,
but that belief meant when somebody got a published graph saying like, “GPUs go up, smarts go up,” and they’re like, “Let’s do this,” right?
Don: I guess where I’m getting hung up is what was the thing that they were buying for $850 billion?
Just smartness? Yeah, I’ll buy, you know, here, 500 units of smart. We can have 1,000 units of smart.” Cool. Here’s $850 billion."
Are they just still buying units of smart? Not a good business plan.
A Business Plan on a Grain of Rice
Adam: No. So yeah, so they built an API, right? So early, like GPT-3, I used it.
So this is before the chat. It was just token completion. I tried to use it before, you would have to… I tried to use it to write tweets for my work, ‘cause I would write a blog post, I didn’t wanna write the tweets. But you would have to be like, give it an article and then a sample tweet, and an article and a sample tweet, and then when you give it your article, then it’s like, “Oh, I get the pattern.”
Don: Complete it for you.
Adam: You couldn’t say like, “Hey man, write me a tweet.” Like it didn’t understand that. You couldn’t communicate with it. Anyway, so they put this on an API. They charge for it. People like it. It’s exciting. Uh, but it’s small, but they’re small, right? But they’re like, “We’re onto something. Let’s raise more money.” And yeah, their business strategy that they were worried about, that they said you could write down on a single grain of rice was, was scale, right?
The word scale, because they’re like, “We have this thing on this API and people are paying for it and it’s, you know, it’s one unit smart. If we had 10 times the amount of GPUs—
We can have 10, 10 units smart,” or whatever the graph was. So they were like, “We gotta go, man. We have this thing, it’s gonna change the world. But anybody can look at what we’re doing and be like, ‘Oh, we could do the same thing.’” Right? There’s no, um, secret sauce from their perspective. They’re like, “Dude, if people knew all we’re doing is trying to get as big as possible as fast, we’ll be in trouble.”
Don: Yeah, so the under- the underlying, um, algorithms are easy to replicate. And, and that’s bad because they want to inevitably be the people that hold the keys.
Adam: Yeah. They had this idea that the first super intelligence that came around would be all-powerful, and so it better be us, ‘cause we’re great upstanding people who control it and not China or Iran or something. Or, or just that guy down the road, right?
Don: Like the same rationale as the atom bomb.
Adam: Yeah, but from a corporate side, ‘cause at this point, don’t think national security’s gotten into it yet. At this point it’s just a bunch of nerds building this thing, right? It’s not… But the US will get involved. Okay, let’s keep going. So in the year 2022, DeepMind, which was a group within Google, right?
Chinchilla Says It’s Not Just Compute
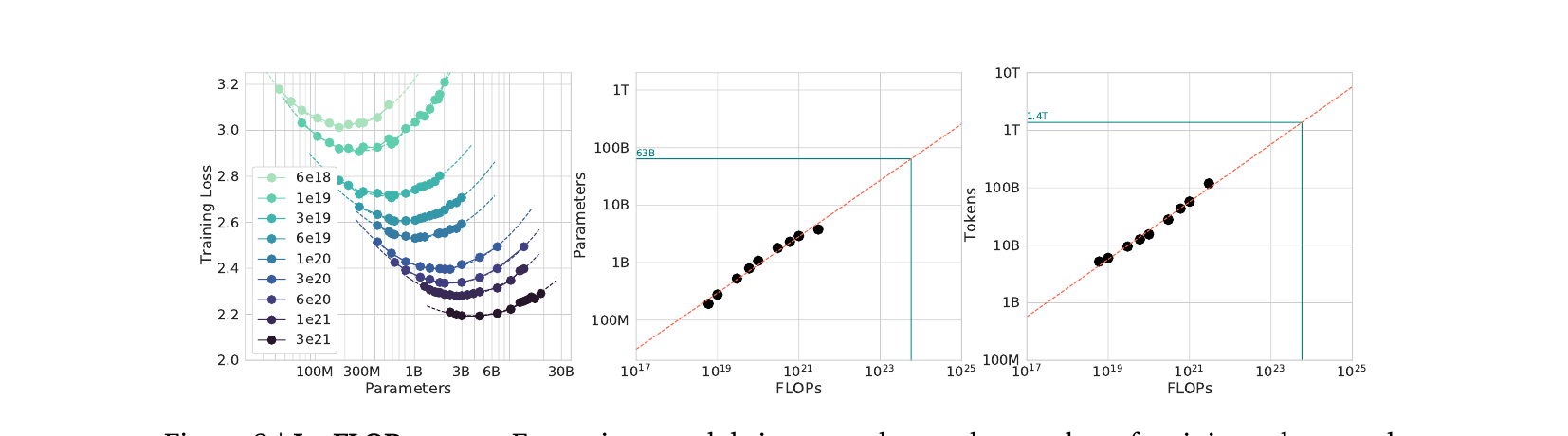
Adam: They published this paper called Chinchilla. So at this point, the GPT thing, you know, it came out of Google. Google wrote a paper, but they didn’t really build anything on it except an internal LLM, and then OpenAI ran with it. Google sees it’s something important and they’re, they keep working on it, and so they put out this Chinchilla thing. And it shows that their graph is kind of wrong—
Don: Oh. That’s not going.
Adam: The Chinchilla people, they built a whole bunch of models of varying sizes and varying training, and they found that, no, there’s actually a very clear relationship. It has to do not just with the compute and not with just how big the model ends up with, but the amount of data that you trained it on. Which makes a lot of sense. You need to give it more information for it to get smarter.
Don: Yeah, it needs to know more so that it can have a bigger library to draw from.
Adam: Yeah. And so you can build it bigger with less information going in, and it’s just, it’s not smarter, it’s just bigger, right? So—
Don: Key factor is the data.
Adam: Yeah, if we can give more resources to this thing, it’ll be better, right? So Chinchilla doesn’t really break it, it just, it adds a new important wrinkle, right? Sounds like it reveals an important factor making it work. It’s not just compute.
Yeah, you need the data.
When Training Became Pre-Training

Adam: And so at the same time, the same month as Chinchilla, OpenAI publishes a paper that they call InstructGPT, guess what InstructGPT is.
Don: Are instructing it to do something, so you’re giving it, uh, data to learn on?
Adam: How would you instruct it?
Don: You would have to feed it similar data for what you wanna accomplish.
Adam: So, I mean, you’re sort of close. But no, this is, um, this is ChatGPT, so…
Don: It’s a different way of asking it to do something.
Adam: Yeah, because before you would give it a bunch of text and it would predict the next token.
Don: So now you’re just talking to it.
Adam: Now you’re talking to it. Instructions, so they call it InstructGPT.
Adam: So the thing that happens, is that becomes the post-training step. So there was training, and now we have this post-training step where we make it more human. But then they decide to rename that first training step where it consumes the whole internet pre-training, which means you end up with this weird world where they have a pre-training step and then a post-training step. There’s no actual training step. Like they’ve accidentally…
Don: They’ve removed the training.
Adam: Yeah, exactly. The training is gone, even though it still exists. Okay, so then mid-2023, start a new training run. Same idea, right? Let’s do an even bigger pre-train. So we’ve trained on the whole of the internet or a lot of it, let’s add even more, right? As we know, I guess they trained it on a lot of books that they probably didn’t properly have access to, but it’s like, let’s feed it more data.
If we understand the formula, let’s make it even bigger. We’ll have an even smarter model. So that’s in mid-2023. They call this Orion, and this was supposed to be ChatGPT-5. So 3.5 was the first ChatGPT, and then there was 4, and they came really close, and they’re like, “Let’s make 5.” Because the difference between to 4 was really big.
OpenAI’s Five Hundred Million Dollar Bet
Adam: And I remember when they shipped it because Sam Altman said something like, “Hey, we have this new model. It’s pretty cool. Not sure if we’ll release it for a long time, but he kind of downplayed it. He’s like, “It’s all right.” You know what I mean? He wasn’t like, “This is the most exciting thing.”
And so this was it was supposed to be GPT-5, blow everybody’s socks off. We’re at the next level of smarts. But they released it as 4.5, and it was super expensive if you used the API, And then I used it a little bit, and it felt kind of more natural. I used it to get critiques on my writing at the time.
Like, “Hey, what’s wrong with this essay?” And it felt like more… It’s hard to describe. It, it felt like more human or something.
So I thought it was great, but they took it away, right? It’s gone. You can’t use it anymore.
Don: What was, uh… Why did they take it away?
Adam: So interesting theories, right? But one for sure is, you know, it was 10 times the size of GPT-4 point whatever, right? A lot more expensive. Like requires 10 times more servers. It’s just– And it, and it’s like it’s a bit better.
Don: Results didn’t scale with—
Adam: Some people were like, “Yeah, no, it’s… I mean, I can tell it’s a bit better.” But you’re like, “Yeah, but it costs 10 times more.”
Don: That sentence more when, you know, the, uh, the results are, you know, maybe not as obvious as you’d hope.
Adam: If I play against a chess bot that’s on my phone, like, it will beat me, right? If I play against, uh, whatever Alpha Chess, the best chess player in the world, it will also beat me.
Don: You know, you don’t notice.
Adam: So yeah, reportedly it’s $500 million that they spent on that first run, and it was, it was, the model was fine, right?
We gotta try again. We gotta get the smarter one. … By that time you’re up to a billion dollars in compute.
Adam: So have you ever had a project this big fail?
Don: No. No, I haven’t. I can speak from experience, I’ve never had $500 million project and, uh, it flop. ‘.
Adam: That’s a huge failure. But there’s also this problem, right? The business case is predicated on that they’re gonna make this forward progress. So it could be devastating. So that’s probably why they did it a second time.
Adam: They’re like, “We’re not giving up on this.” In the middle of this, Ilya, the guy we’re talking about, he left. So he just, he left OpenAI. Not a good sign.
Don: There has to be some kind of mitigating factor to why… Up until this point, they’ve been operating on the premise that if they just give more compute and data, that it will increase according to this chart.
Adam: Yeah, we shall find out.
Right? I think, uh, a lot of people have this perception that these labs, like OpenAI, they’re huge, they’re making all this money, they’re sitting on these big piles of cash.
People are paying them for this product. It’s an amazing place to work. But if you think of it, it’s really high stress, right? Like they need to keep this promise going. It’s very important for their valuation that they’re always able to have the next exciting model. Like the whole thing is premised upon, you know, number go up—
Don: That’s, that’s most corporations and—
Adam: But just being the hottest one with this huge valuation, and it’s not like Apple where they have phones and stuff installed. It’s like they have this API that you call, and if it’s not getting better, and if there’s alternatives, like it’s just, it can very quickly…
Don: And I guess the thing is that when people didn’t like it and you say, “Well, why?” it’s like, well, didn’t… It just didn’t feel as good. It’s like, are the results based on feelings? Do they, how do they quantify I guess?
Adam: The benchmarks, right? In the, uh, early days, they tested against like the LSATs, like lawyer tests, the GRE, like graduate tests. Again…
Don: And then, when they had the $500 million model and the 10 times more expensive, did they perform those benchmarks and it was like way better? Was it like 10 times better?
Adam: No. No, it was like a little bit better, right? It was…
Don: Was like- Oh, okay. So that’s what they’re basing this result on. It’s not- Oh—
Adam: Yeah. It’s, you got an 82, it got 84, and you’re like, “Oh, but it’s 10 times better.” And you’re like—
Don: And maybe it’s one of those phenomenon where like, yeah, but that last 10%, like being perfect, it’s very hard. It’s way… It’s like a logarithmic scale, right? Where you could put in 10 times, but you’re not gonna get 10 times improvement on that score, right? You’re gonna have to put 100 times in to get, you know—
Adam: Yeah.
Don: Percent. It’s the final 10% is the hardest.
Two Years of Trying With Nothing to Show
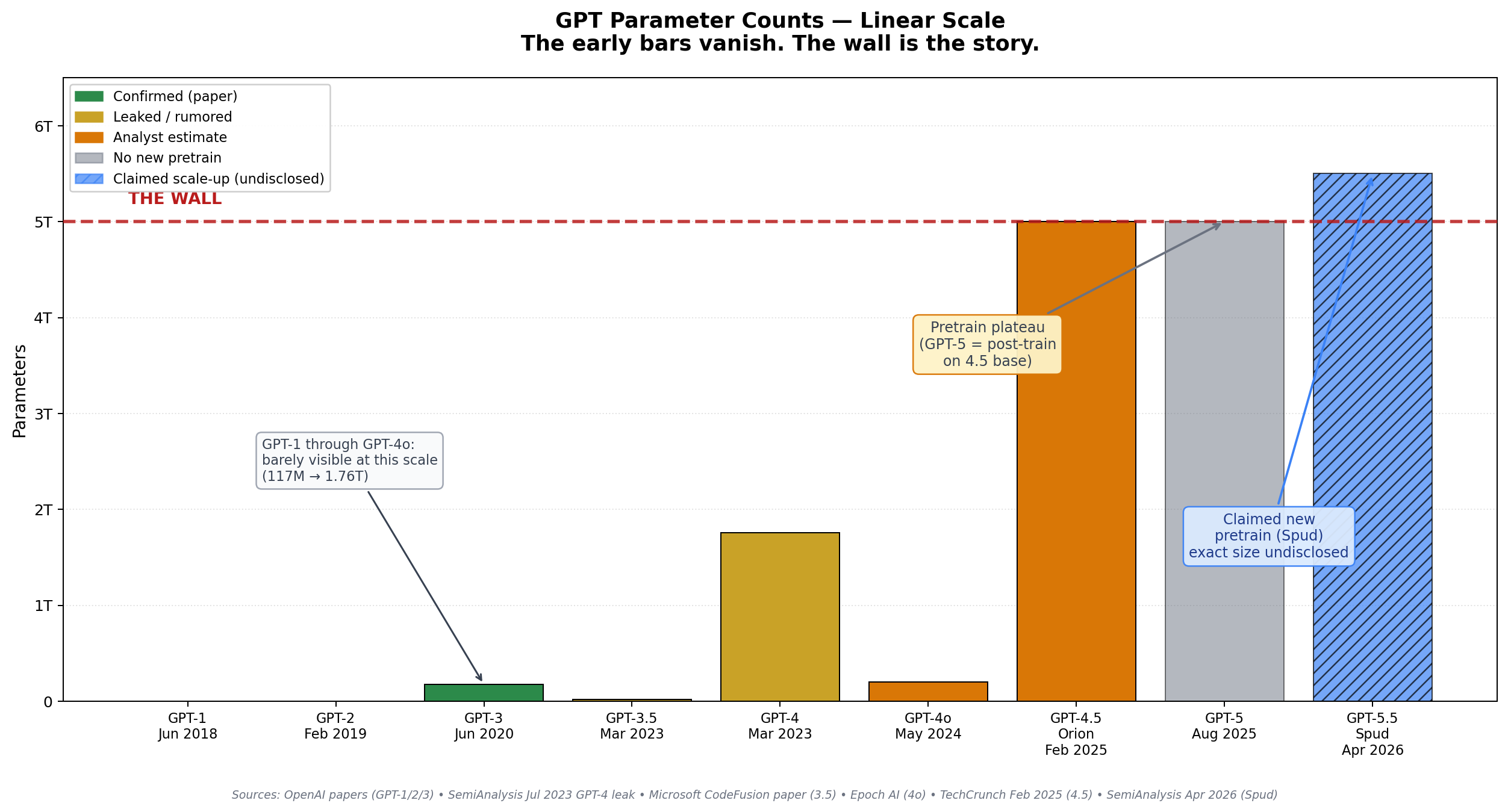
Adam: So this goes on for two years. So they build this giant model. It’s, it’s not great. And SemiAnalysis, an industry research place says like:
“OpenAI’s leading researchers have not yet completed the successful full scale pre-run that has been broadly deployed since May 2024.”
That was GPT-4o.
So that’s not good, right? It’s like the main thing they do, they haven’t been able to do a new one and, and time is passing on, right? Internally, you have to imagine they’re trying all these things and, but they’re not moving things like they see. And even inside, people didn’t really agree on why this wasn’t working. So they looked into it and they couldn’t figure it out?
Well, I mean, what’s your guess?
Don: Something to do with, uh, the core way in which it operates, it got to the point where more hardware isn’t gonna actually make up for improvements in the algorithm.
Adam: So in December 2024, Ilya who left, so he left OpenAI. There was a whole kerfuffle with, he tried to get Sam Altman kicked out and, uh, he failed at that.
Don: Corporate drama.
Adam: Yeah, corporate drama, right? The, the researcher guy tried to make a power move and the executive people…
Don: They’ll make a movie about that someday.
Adam: Yeah, right? Anyway, so he starts a new company and then he’s at NeurIPS. He’s at this big conference where he’s being presented an award for his great earlier work that led to all this and he gives a talk.
Don: Pre-training as we know it will unquestionably end. Why will it end? Because while compute is growing, better hardware, larger clusters, the data is not growing. But we have, but one internet. You could even go as far as to say that data is the fossil fuel of AI.
Adam: So they made these early versions. They scrape a lot of the internet, they scrape all these books. They, they feed it to it and it’s great. And then you’re like, “Okay, we need 10 times more.” So, okay, we used to download the source code on a GitHub repo. Now let’s get every revision, right?
Let’s get all the history. Well, it’s just less good data, right? Or we got every Reddit You know, important posts, let’s go to the really obscure forums or let’s… It’s like there’s just less good data out there.
Don: Well, it seems that they’ve reached the limit to what the core algorithm can actually solve given its data, we operate every day without the whole internet to figure out answers to questions, right? So if you need the whole entirety of the human internet.
To be a little bit better, then maybe you’re not using the data you have as efficiently as you should be—
You’ve eaten all the good parts, and just there– only the crumbs are left, and they’re not gonna get you where you wanna be.
Adam: Yeah. I agree. And so they call this, uh, the pre-training wall, Pre-training was the original training that they renamed the pre-training wall. They’re like, “We just can’t… There’s nothing here.” Like it’s, “We can’t get past this.” We’ve, uh, or as Ilya says it, right, there was these fossil fuels, which was all of the internet and all these books, and we ate it all.
We’re out. We’ve e- we’ve hit peak oil. There’s nothing left. We, w- this is, so they have to find another way, right?
Don: Uh-huh.
How AlphaGo Points the Way Out
Adam: Okay, so to understand what happened next, how these improvements happened, we have to go back to DeepMind, right? So DeepMind was the people who released the Chinchilla paper, but the more important thing was, I don’t know if you remember, like, a decade ago, there was this AlphaGo. Um, do you remember that? The game Go.
Don: Yeah, yeah, I remember that.
Adam: These guys, they had this DeepMind company, got bought by Google, and originally, they started it playing Atari games. Then eventually they did Go and then chess, and the way that they trained it was this reinforcement learning. So they create something, they get it to play Go against itself, and then whichever one wins, they let that one continue, make two copies of it.
Don: So, like, kind of like a evolution type thing.
Adam: Yeah, so, it learns, but uniquely it doesn’t need the internet. It’s not reading Go books, right? It’s playing Go.
Don: Creating its own data.
Adam: It’s creating its own data by playing the game against itself. And when they originally created this, Go was considered uncrackable, and then they had this big, Google had this big tournament against the best Go player in Korea, Lee Sedol. And nobody thought that this thing would beat him. Uh, and of course it crushed him because it had been playing Go against itself for the, a compute equivalent of the zillion years, right? It’s just learning and learning and learning. So it’s creating its own data, as you said, right?
Which is a great solution to this problem. But it needs a scoreboard, right?
Don: You– somebody has told it what is the preferable outcome.
Adam: Yeah, like in a game, there’s rules and you know when you win, right? So you can generate data because you can always figure out “Oh, did I win?” yes or no. So they started with this training, right? That became pre-training, and they added on this chat thing, the instruct. Now they add on this new step, which is, uh, reinforcement learning, so they call it RLVR.
Adam: But basically, they need ways to have a, an action that we need the LLM to take, where we can verify if it got it right or not. So can you, what’s an example of something that’s easy to verify if you got right? Like math.
Don: Right? Yeah, math or anything that has, like a right or correct answer, right?
Adam: Or I think the most impactful one of recent years is coding, right? You can write code.
Don: And it will work or it won’t.
Adam: It’ll work or it won’t, right? You can run the compiler, see if it worked.
Don: There’s some nuance there because, uh, you can write code that will work but isn’t good. Oh, cheap shot.
When LLMs Start Grading Themselves

Adam: You shot. Yeah. And so the cool thing is that, um, they just lean into this, right? So this is a new way to generate data that OpenAI comes up with in their panic, and they kind of keep it to themselves. But if they can ask the LLM to, yeah, to come up with a solution to a bunch of calculus problems, and they ask it to think out through all the steps, right?
So let’s ask it 12 times with random problems to solve this calculus problem and think it out step by step. And most of them are wrong, but maybe one is right. And so then they take that one where it got it right, and they can feed that back in as training model, like update the weight. And they just start doing this in loops, right?
‘Cause once they get it to successfully do some calculus, then they update all the weights. Now it’s a little bit better, and they can give it more problems, get more right answers—
Now they’re doing this DeepMind, like Go thing, right? They can take their LLM and do thousands and thousands of generations getting better at problems, as long as the problem has somebody to say like—
Don: Or not?
Adam: So, now they’re generating their own data. So this becomes O1, this GPT model. And so in a way, it’s like they had this wall of training, and they hit this wall, and then they found just a new dimension, right? So they can grow by generating their own data in another direction.
Don: Yeah, I mean, that, going back to his analogy of how that’s the fossil fuel of AI. They’ve just come up with a more efficient combustion engine.
Adam: Or a renewable resource, right? Because here, you take the LLM and it can play its own games, and if it succeeds, you’re feeding that back in, right?
Adam: So it’s renewable in that it’s generating its own data if you have a way to score it, right?
Adam: I mean, in the pl- places where you can verify the answer, it can learn. But okay, so in February, so now we’re coming close to modern day, right? So in February 2025, we haven’t even talked about Anthropic, but Anthropic releases Claude Code. And the cool thing, I don’t know where it happened with them, and they’ve never confirmed it, but all of a sudden these LLMs, they don’t necessarily start doing a lot better at all different trivia, but they just start getting super good at coding.
And the theory that I think is pretty much confirmed, right? Is Anthropic builds Claude Code, but they can train on Claude Code as well, right? So they have all these problems, and then they can run Claude Code through it, and then when it works, they’re like, “Good job, Claude Code,” and they reinforce it.
And so it gets better and better at coding. It’s not necessarily better at all kinds of other things, but this is a very clear signal. If we have a bug on this project and it can solve it, it learns to get better and better at these things, right?
Why Washington Crippled Nvidia’s Chips

Adam: And so that makes, but that makes all this synthetic data, right? If they have Claude Code run on a problem and it solves it correctly, then th- you know, they end up with this thing where it’s step through things. They’re creating their own data, as we said. But this is a second big breakthrough by OpenAI, right? They have a new way to generate more data. They kind of keep it closely held.
But at the same time the government is getting antsy about, you know, AGI. The US is like, “I hope we get AGI and not China, and then they outsmart us and destroy the world.”
Or maybe the other idea is the government’s just worried, “Hey, this is gonna be huge industry. We want this industry to be American.” Right? And so they start putting in place controls on NVIDIA, telling NVIDIA like, “Don’t sell GPUs to China. We just don’t want that.” And then NVIDIA doesn’t love that ‘cause they’re like, “We like to sell these things so we make a profit on them,” right?
Companies can buy these NVIDIA GPUs, but they are, um, handicapped. So they’re super good at doing GPU stuff, but they have a very low memory.
Don: Well, they did that back for, uh, Bitcoin mining too. That’s when it started.
Adam: But now a ta-, it’s not a tariff, I guess, but it’s like a export constraint. The Chinese just can’t get the ones that you can buy here.
Don: Yeah, there’s proprietary processors meant specifically for AI that Nvidia makes.
Adam: They’re not allowed to sell them, yeah, to China.
DeepSeek Builds AI With Tied Hands
Adam: So in China, um, there’s this company called DeepSeek that we talked about at the beginning. And they spun out of this hedge fund because the hedge fund wanted to do all this machine learning, I’m assuming, to predict the stock market. They decide, “We’re gonna build our own AI,” right?
Don: And because they couldn’t get the Nvidia chips—
Adam: Yeah. So they could get the NVIDIA chips, but not the really high-end ones. They could get the less high-end ones, and so they couldn’t get the H100, which is the Frontier Lab ones that cost like $30,000, you know, per. And you end up… In the server, they end up putting eight of these in.
So they’re very expensive. I mean, they would’ve bought them, but they weren’t allowed, right? So they could only get this one called the H800s that just are much less good at talking to each other. And the problem is you need a whole cluster of these to make it work. And so DeepSeek is like, “Hey, we gotta crack this code,” right? They released a paper about h- what they did, so here’s one of the things.
Don: Low precision training is often limited by the presence of outliers in activators, weights, and gradients.
Adam: So this is one of their tricks, where they they were able to lower the bits. It’s like they’re running a, like an N64 game on like a NES 8-bit. Like, they were able to lower the bits without losing the, um, accuracy somehow, which let them—
Don: Like MP3s—
Adam: Yeah. And then—
Don: They’re able to do more with less. Only 20 SMs are sufficient to fully utilize the bandwidths of IB and NVLink.
Adam: So what happened there is these things were handicapped at how quickly they could network to each other, and so they found a way to use some of the layers as a network card, so that they could more quickly talk to each other.
Don: We employ customized PTX instructions and auto-tune the communication chunk size.
Adam: So basically they figured out the instruction set, or maybe it’s known for NVIDIA GPUs, and instead of using the normal SDKs, they wrote in assembly how the instructions would work, sidestepping how NVIDIA does things so that they get performance speed up.
Adam: And so they published this whole paper on this. They published this new LLM, and it blew people’s minds. It’s a more gritty approach, right? We’re constrained, so we need to come up with a different way.
Don: Yeah. I mean, and that’s how, that’s how a lot of things were back in the early days of, you know software development. … And you had to be very aware of how many bytes of data certain fields were because you only had so much to work with.
Adam: So the government, like the US government tried to prevent China from getting a heads up by putting these constraints in place. But the constraints actually just cha- taught these Chinese companies how to, how to do with less, right? Maybe it even advantaged them because now they can operate on a, on a smaller budget.
Don: Yeah, no, I remember when the, when this happened, they came out with like their, um, their DeepSeek, and it was NVIDIA was freaking out because they’re, “Well, if they can do this with their constraints, what’s gonna happen to us,” right? Gravy, the gravy train might be coming to an end here because obviously, you know, we have all the unlimited hardware, and we can’t perform as well as this.
It’s almost like we should have been looking at how to optimize our AI instead of just throwing hardware at it.
Adam: Oh, yeah. Yeah, exactly. So they published in their paper that it cost them to do this, Oh, $5.6 million, which was a little bit misleading because they were only talking about one specific stage of the training. But that got published, and people were using it, and they’re like, “This thing’s amazing.” And meanwhile, OpenAI is saying, “We spent a billion, and it didn’t.”
Don: We didn’t get the same results.
Adam: Yeah, we didn’t get an improvement. Yeah, everybody panicked, right? The NVIDIA stock fell. Everybody was like, “What’s, what’s going on here?”
DeepSeek Just Publishes the Secret

Adam: Other thing that happened is when they published this paper and they released this model that they called R1, so one thing is this has to do with the moat, right? So we found ways to work with less. The other thing is the DeepSeek people publish in their R1 thing this whole reinforcement learning idea. The OpenAI, this is their new secret, right? They’re like, “Oh, we can give this thing rewards, have it think out, Provide this feedback.”
So R1 uses the same trick. They, they came up with it on their own. “Hey, try to solve these problems, try to think it through, and we’ll take all these results, and then we’ll feed them back.” And they publish exactly how they train it. OpenAI’s new trick that’s gonna blow away the market, this Chinese company just—
Don: It’s just open.
Adam: Just put it in a PDF and put it on GitHub, right?
Don: Eventually, enough people are gonna come to the same conclusion independently. I mean, that’s how most inventions happened, right?
Adam: Maybe, but, not right away, right? And, and…
Don: Oh, right away. Yeah, I guess they were hoping that they could keep that secret a little bit longer. That’s our secret sauce.
Adam: That’s our secret sauce.
Yeah, so they called it, RL on verified reward loops, and they described this multi-stage pipeline and that there was this aha moment where they saw after doing this feedback that the, the LLM started to talk to itself and say like, “Oh, that seems like the wrong answer.
Maybe I should try this.” And in its thing, they’re seeing like, oh, whether it’s thinking or not doesn’t matter, but it’s starting to be able to put out reasoning loops of following a chain down one path, backtracking, going down another. They’re like, “Oh, we’re onto something,” right? So they get these reasoning loops where it’s succeeding.
It’s like thousands of generations of it generating a bunch of questions, verifying which are right, feeding it back in. It’s, it’s learning. It’s generating its own data.
And they just put the model out open weight for people to use. They put out “here’s how we built it,” right? Because they’re part of a hedge fund. Like, this isn’t how they make their money. And it’s like, oh my God. This is a crater into this whole capitalistic venture of building these amazing models, right?
Is because, on the one hand, AI models, they’re amazing. The work that they can do, it’s ridiculous, right? But it’s just the most, it’s such a powerful tool. But at the other hand, yeah, you create it, and then somebody else is right behind you, and then quickly the value of them is going towards zero.
Don: Like, into– use an older analogy, if you think way back in the day when, um, you know, they came up with TCP/IP, and if they had to wall that technology off and be like, “Only we know what TCP how it works,” right? Somebody else would have figured it out—
Adam: Yeah. Yeah. Yeah. It’s like networking, because networking is very much about connecting. But yeah, I get your point.
Don: Yeah, it was a technology that, you know, they could have held onto it and said “This is how, this is how it works, and now we are the holders to anybody who wants a network. Proprietary technology that makes networking work, and you have to pay us a license to use it.” But other people are gonna figure that out eventually, right?
Or they’ll come up with an open standard and be like, “Well, you know, everybody should use this because it’s easier.”
Adam: Yeah, exactly. So if you, if you go back to where we started, right? We have this pre-training that’s actually really training, and then this thing to make it chat-like, and then this thing to do this reinforcement to generate its own data. So DeepSeek figured out how to do this part, right?
That nobody else could, and they figured out how to do it very cheaply. But, doing that first step of consuming the whole internet is still really expensive, right? And so, you could think, “Oh, that’s a, that’s like a moat.” Like, getting all this data and putting it together.
Don: And the barrier in there is higher because you have to consume the whole internet, and that’s something that’s logistically hard to do.
When Llama Leaked Onto BitTorrent
Adam: Yeah, but enter Mark Zuckerberg, right? So at the similar time, I’m not sure the exact timeframe, right? … Facebook, Meta, they start building their own base model. They, “We don’t wanna be left out of it.” And then when they release it, they say like, “Hey, we’re not actually in the business of, of being like a, an LLM-serving API or something. Like, we’re, we sell ads about I don’t know what their ads are.
Don: Yeah, I don’t, I don’t use Facebook.
Adam: Yeah. And so they say like, “Hey, if you’re a researcher, you can just, uh, download our model. Just ask for permission and you can download it.” And so they do that, and then, um, very quickly, one of those researchers downloads it and just puts it on BitTorrent because they’re like, “Yeah, why not?” And then Facebook demands that they, the Meta, I guess, demands that they take it down, and then, but it’s too late.
And so, um, they change their stance. They say like, “No, this, I mean, you can use this if, uh, for non-commercial purposes, just grab it and use it,” right? And this becomes, uh, Llama. So this is the first, I think, open weight model. If you have the GPUs that you can run this on, you can just grab it and use it for free. So Facebook spent whatever, the $500 million to consume the whole internet, which is weird, right? Why would they do that?
Don: I don’t know.
Why Meta Gave Llama Away

Adam: Here’s what Zuckerberg said. In the early days of high-performance computing, the major tech companies of the day each invested heavily in developing their own closed source versions of Unix. It was hard to imagine at the time that any other approach could develop such an ad- such advanced software. Eventually, though, open source Linux gained popularity.
Today, Linux is the industry standard foundation for both cloud computing and the operating systems that run most mobile devices, and we all benefit from superior products because of it. I believe AI will develop in a similar way. And that makes sense to me, right?
Don: It’s like the premise of open source software.
Adam: So th- there’s this business strategy. I heard about it from Joel Spolsky, and it was called Commoditize Your Complement, right? And so if you sell a product, and along with this product something else is used, if you can actually decrease the cost of that thing, it makes your thing more valuable, right?
Like if electricity is super cheap, electric cars are more valuable, right? So if you’re an electric car company, if there was some magic trick to make electricity cheaper, it would help the value of your car.
And so Meta’s like, “We’re not in the business of LLMs, but we’re gonna need them,” right?
“We’re gonna need them to judge if somebody’s spamming comments or, or whatever,” right? “We don’t wanna pay these exorbitant fees for OpenAI or, or whatever. We’ll just build our own, and then ‘cause it’s not our business, we’ll just give it away. And it also allows me, you know, probably to give the finger to these other companies,” right?
Don: Yeah, subvert them.
Adam: Subvert them in a way, right? So that’s what they did. So that erodes another thing, right? Now the base thing that’s very expensive, you can just get it, and maybe it’s not as good, but, but it does exist—
Don: Yeah, it creates a atmosphere of competition.
Adam: Exactly, right? Except he’s not doing it, uh, nec- it’s not necessarily for charitable reasons. And then it’s helpful, from his perspective, he’s like, if we make the one that we give away for free and everybody else builds on it, we benefit from all of those things.” If you build some ORM internally that’s a crazy Don creation, you have to maintain it and whatever. But if you build one and then release it and the industry starts using it, they make improvements, and then you can pull those in, right?
Don: So there’s a, there’s an interest in increasing their own business.
Adam: Yeah, I forget where I am. So yeah, what were the original texts that I sent you. Did we– Have we answered any…
Don: Yeah, and no, I think we have. We’ve covered it. Because R1 is on GitHub, Llama’s on Hugging Face, and what’s this 880 billion for?
R1 was the model that DeepSeek came up with. So it is, it has the more efficient, uh, algorithm because they were constrained by hardware restrictions. So they came up with a better, a better way of doing it that wasn’t locked into, you know, Nvidia’s model. And, uh, Llama was the, was the, uh, Facebook training model that had all of the internet included in it, so you didn’t have to go through all the work of, of combing the whole internet.
There’s no, there’s no s-s-secret sauce.
There’s no special sauce. Everything’s open. You can, you can get a model. It’s all, it’s all out there for people to develop. There’s no, um, there’s no reason why somebody couldn’t make our product.
Adam: Then I think the only thing we haven’t answered is the very first part, right? Which is like Greg Brockman being like…
Don: Oh, the, the “I think of Spud as a new base model,” like a new, a new pre-train.
Adam: It sounds like he’s saying, “We’re two years ahead of everybody else.”
Spud and the Two-Year Lead

Adam: So Orion we talked about, that was their $500 million and then a billion dollar run that just didn’t amount to anything. Became, it became 4.5, but then they pulled the plug on it. So Spud is one of their new models, and so Brockman in that video I shared was from a couple days ago talking about Spud, their internal model, and then they released it, so it became GPT 5.5, right?
Six days ago they released GPT 5.5. It says, “A new class of intelligence for real work.” Okay, well, every time they release a new model, they say revolutionary, right? Yeah.
But there’s some interesting things going on here, right? And I think his quote is the only thing we haven’t unpacked.
Don: It’s the new base– It’s the new pre-train.
Adam: It’s a new pre-train, right? But so what is it? Because we discussed this problem wherein they keep– they tried making them bigger, but there was no good data, they made one 10 times the size and it wasn’t better. Now missing returns. Diminishing returns, and now they have another big one. So what, what is their secret?
Don: Yeah. Well, wait a couple weeks. It’ll get leaked or you’ll figure it out.
Adam: Cause there’s this other problem that happens, right? So there’s this process called distillation. So if I am building a new model, I have this 4.5, let’s say, that was super huge, very expensive to run, and was a little bit better. Well, I can chat with it and similar to this reinforcement learning process, I can take that chat log and I can take a smaller model that’s not giant, and I can train it on that, right?
And so it’s learning from the bigger model.
It’s like it’s teaching a small model that I can run, at lower cost, the great answers that the bigger model had. And it can’t learn it all because it’s just, it’s not as big, but it will get a lot closer.
Don: It’s like a senior teaching a junior, right? It’s like I went through some, the last 20 years of I’ve—
Adam: Seen some stuff.
Don: seen some stuff. You don’t have to do all that. You don’t have to make all my mistakes. Just do this.
How Smart Models Leak Through the Cracks
Adam: Yeah, and so they call this distillation.
Don: And if it’s like my son, he won’t listen to me.
Don: He’ll make the mistakes anyway, and then he’ll be like, “Oh yeah, it turns out you were right.”
Adam: That’s the learning process. But the big labs do this themselves, right? There is like GPT-4.4 and there’s like GPT-4.4 Mini. And Mini costs less and it’s still really smart, but it’s much smaller and faster and because they took this big model and they distilled it. They got all these important lessons from it and gave it to the small one.
Well, OpenAI and Anthropic made all these allegations against DeepSeek and other open weight companies that this is what they’re doing. Because whenever there’s a new super smart model out, six months later.
The only thing that you need to do this distillation really is the, is the logs of chats from these smart models, which is in fact their product. If you want to make a smarter model and I have one, just have lots of chats with my one and then train your model on it.
So it’s even more like competitive pressure, right? If I come up with a really smart model by definition you can use it to make yours smarter. So this is another moat problem I guess, right? And if you look at OpenAI, they have these thinking models, but it won’t actually tell you what the thinking is.
Don: Well, they don’t want people to know how it’s thinking, ‘cause that’s their trade secret.
Don: That, that’s their secret sauce,
Adam: And so even without that black box, they’re still alleging, I don’t think they’re lying, that these Chinese labs and other open weight companies are just using their service and using that to train their models because why not—
Don: Then you can use their models and you can see exactly how it’s reasoning.
Adam: Yeah, but so every time they come up with a super smart model, a couple months later, probably there’ll be a new smart model from the open weight companies because it’s easy to extract things, right? It’s like the problem of MP3s. It’s easy to copy this information. Not as easy as an MP3, but sort of easy. The moat is leaking.
Where Is the Eight Hundred Billion Hiding?
Adam: So if we go back to the 880 or 850, what can be… Where’s that value hiding, right?
Don: Oh, I think a lot of investors are asking as well.
Adam: But I’m not so negative on OpenAI. I think they could be a very valuable company. But where is that value?
Don: Well, what’s the good way to try and get some money? They’re not subscribing. We, we do have subscriptions.
Adam: I mean, I’m a subscriber.
Don: Yeah, but I think that overall, the money that they get from subscriptions isn’t at the levels that they would need in order to call it a success. So ads, man.
Adam: That’s the worst. I don’t want that.
Don: That’s, I think they’re talking about it. That’s how they have to monetize, right? There are a lot of people who are using their product. Even though there are alternatives. Brand loyalty.
Don: yeah, brand, whatever, but, uh, it just means that you’re gonna have to meet them where they are.
Adam: I don’t know.
Adam: Businesses are using… Think if you look at it frozen in a moment, right? The amount of spend that my company is spending, so it’s Anthropic, but it could easily be OpenAI, just for coding subscriptions, right?
It’s massive. Like the amount of money we’re pouring into this company is huge.
So I think at any given moment, that’s real, right? They’re making a profit off that. But the challenge is, yeah, that it can quickly diminish when there’s competitors.
Don: Well, if there’s an open source alternative as well, right? Like, w- why would your business keep paying a subscription for hundreds and hundreds of dollars on credits when they could just, you know, use this open source alternative that’s maybe even locally hosted?
Adam: Yeah. Or just there’s a company that hosts it, you know, at cost ‘cause they didn’t have to build it, right? The open source model, they grab it. Lots of those exist, So it’s a Red Queen’s race, right? There’s… Have you ever heard this term before?
The Red Queen’s Race
Adam: I love this term.
So it’s like “Through the Looking Glass” from, uh, “Alice in Wonderland,” and the Red Queen has a race and they’re running, right? And Alice says like, “Why aren’t we moving?” Like they’re running and it’s like they’re on treadmills and they’re not going anywhere. And Red Q- the Red Queen says like, “Oh, here, you have to run as fast as you can just to stay in the same place. If you slow down, you go backwards, but as fast as you run, you stay in the same place.”
Don: No one can ever win.
Adam: Yeah. As soon as you have an advantage, keeping that advantage requires working just as hard as you did before. It’s a great metaphor for, f-for this process, right?
It’s like, okay, every year or so, OpenAI is coming up with a new breakthrough that lets them push the frontier, or Anthropic is. So the open weight models right now are all, let’s say, six months behind. Maybe, I don’t know about this new release, but previous to, uh, Brockman saying we’re two years ahead, the, the gist is kind of the open weight models are six months behind. But s- in that six months, the model’s got so much better that everybody’s paying for the premium service.
Don: Yeah. Well, it’s like movie theaters, right? You can go see it in the theater, it’s very expensive. You get to see it first I– there’s a lot of people who just wait.
Adam: If you wanna be six months behind, you can use a cheap model and it’s fine. But right now the curve is so high that it’s no, you gotta get on the new thing. Everybody feels that way. If that curve flattens out, it’s over, right? If that curve keeps going up though, oh my God, who knows where we’re gonna end up?
It’s the Red Queen’s race. They, all these frontier labs, if that’s their product, they’re running as fast as they can to stay, right? Like right now, ChatGPT has my $20 a month. Anthropic has my $100 a month for the coding agent. But if something better comes out than those, or just everybody else catches up and has a cheaper service that’s sold at cost, that money’s gone.
Anthropic has to go as hard as they can just to keep my money. ‘Cause I’ll just switch. There’s this line from Stewart Brand. People always remember it as, “Information wants to be free.” But his actual quote was, “Information wants to be free, but information also wants to be expensive.”
Some information is just so valuable. But at the same time, it’s free to share it. And these companies are in this place where they have something that’s so amazing, this, uh, amazing breakthrough with these AIs that are so valuable, but yet it’s depreciating like nothing.
Like a, like a peach on like a summer day. Because everybody’s catching up. And so he comes up with this new thing, right? Brockman’s two years of research is coming to fruition. That’s not modesty, right? He’s trying to tell people, “Hey, actually, I think we’re more than six months ahead.”
But the news came out. So SemiAnalysis, who we talked about before, they said this is the first new scale-up in pre-training since GPT 4.5, bigger model. So they’re back on the curve, right?
So this curve that we followed this curve up so far, and then they could never get past it. Now they’re claiming we’re up. We got past this wall. Ilya said there’s nowhere else to go up here, but we.
We found a spot, right? Ilya left the company. We’re here. We found a way, right? There’s these two founders, one the, the engineering guy and one the researcher, and the researcher left and said, “Fossil fuels have been exhausted.”
GPT-5.5 Costs Four Times More

Adam: But they’re saying, “Hey man, no, actually it’s still going. We found something.” What, what are their fossil fuels? And one interesting thing is usually these GPT models have been getting cheaper and cheaper over time. This 5.5, uh, that they just released, costs four times as much per token, per conversation.
Don: Okay. So it’s obviously gonna be more of a moneymaker then.
Adam: Well, maybe. But 4.5 was also super expensive, and then they pulled it, and the reason is these things get bigger. They just become more expensive to host. They’re like, “No, man, this costs more.” Like this is a big ‘un, right? This is a chunky model, the biggest we’ve ever shipped.
Don: But will the results be like compelling enough for somebody like yourself-
Adam: Is it worth it, right? Four times more is a lot. So I don’t know. And whatever, the podcast will go out. Somebody’s listening to this and it’s a year later um, and we’ll know. But it doesn’t matter ‘cause this is the next one and the next one and the next one. The race keeps going.
The Cat’s Already Out of the Bag

Adam: I could not get a subscription and use this open weight model from a, a number of providers, or I could just pile up some GPUs here and run it or, or whatever. I have friends who will say, “Hey, th- this is all a trick. The OpenAI gets us addicted to coding using these coding agents, then they’ll jack up the price and everybody forgets what coding work-”
Don: That’s what I was, that’s what I was, um, worried about … It’s, it’s a, it’s a risk for your company, and you wanna limit the exposure that you have to that risk. If they start relying on it, then the risk is that Anthropic could jack the price by four times.
Adam: Yeah, but I’m saying, hopefully, I’m showing why there’s less of a concern.
Don: If you can jump to a free model.
Adam: Because the free models are always just a little bit behind. These companies are actually fighting tooth and nail with each other. If both Anthropic and OpenAI collapse, we’ll just lose the latest six months because everybody’s racing to keep up.
These things are not going away. You can, you could torrent that Llama version, it’s not at the lead anymore, but people use that Llama as the base model. They add all their training on. They do the distilling that Anthropic and whatever is mad at. And if all of these companies explode, we still end up with just the open weight models of six months ago. And there’s a bunch of companies that host these, and you can use like OpenRouter.
Don: Yeah, the cat’s already out of the bag, right? Like
Adam: Cat’s out of the bag, this isn’t going away.
Close
Adam: Okay. We gotta wrap this, though. Okay. So, let’s go through it again. So what were the original q-quotes?
Don: There were, there was like, Where the OpenAI president says, “I think of Spud as a new base, as a new pre-trained.” And then there was the Google memo that was like, “Guys, we don’t have any moat, and nobody does.”
Adam: So what’s your feeling? True, false?
Don: Oh, the memo leaked, well, uh, well before the announcement of that new base model, right? So it could have been true at that point, but maybe it’s not. Maybe the moat is now in the new, the new base model.
Adam: See, I feel like it’s still true because, Brockman may think that they have a moat, but he’s saying, “We have a moat that’s two years.” And, not very long.
Yeah. He’s like, “We think we… No, no six months this time. Now we have two years.” that’s, we need to reinvent ourselves in the next two years or…
Don: Yeah, it seems like the underlying premise of them having something over other companies is temporary, it’s still, so it can’t be something that won’t eventually be discovered.
Adam: Yeah, so what do you think? We have no moat and neither does OpenAI. True or false?
Don: Um, I feel like it’s false.
Adam: Oh, I feel like it’s true, but yeah, interesting. I mean, I guess it depends on the timeline, they have one, but it’s a temporary one. And they maybe have one for now, right? But when that one gets bridged, they will be stuck trying to dig out another one.
Don: They do have one, but it’s not, it’s not permanent.
Adam: Yeah. Okay, and then the first quote, I think we understand. So he says, “I think of Spud as a new base, a new pre-train, and it’s two years’ worth of research coming to fruition.” Do we…
Don: So the two years of research doesn’t mean that they have two years of before somebody figures it out. Like, you could spend a lot of time on the research and development, and then release it and somebody copies it.
Adam: Third one?
Don: So the quote is, “If all this stuff is already built, why are you paying 850 billion?” Like, what are you buying with that?
Adam: Yeah. I think we actually agree on what the answer is. The answer is people are betting on this horse. They’re saying, “We know this one moat is only gonna last so long, but we think this company will build the next moat—”
Don: They’ll keep the treadmill going.
Adam: Let’s keep the treadmill going.
Don: Everything’s on open source. Why are we spending money buying $850 billion of something I can fork today?
But you’re not buying that. You’re buying a process.
Adam: So I think we understand it all. I think we got through it. What do you think?
Don: Yeah. No, I think we figured it out.
Support CoRecursive
Hello,
I make CoRecursive because I love it when someone shares the details behind some project, some bug, or some incident with me.
No other podcast was telling stories quite like I wanted to hear.
Right now this is all done by just me and I love doing it, but it's also exhausting.
Recommending the show to others and contributing to this patreon are the biggest things you can do to help out.
Whatever you can do to help, I truly appreciate it!
Thanks! Adam Gordon Bell
